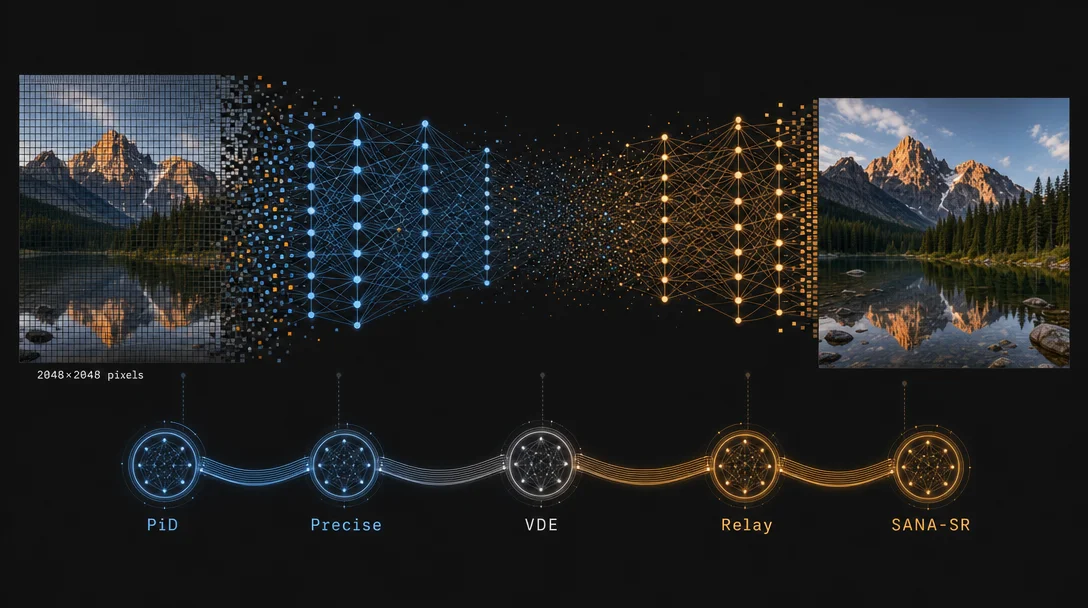
Five diffusion papers worth reading today (May 25, 2026)
Monday's weekend-gap batch covers five papers that each remove a specific approximation from their respective pipelines. NVIDIA's PiD unifies latent decoding and upsampling into a single sigma-aware pixel diffusion step, reaching 2048×2048 in under one second. Tencent Hunyuan's Precise introduces SDE-consistent stochastic sampling for flow matching RL post-training, cutting wall-clock training time by 13–53%. SCUT's VDE (CVPR 2026) replaces velocity caching with a decompose-and-estimate approach, achieving 3.22× speedup on Flux. The UMass/UofT/Stanford Relay paper adds per-token relay channels to masked diffusion LMs, reducing inference latency by 32%. SJTU's SANA-SR delivers 0.019-second one-step image super-resolution at 344M parameters.

研究速览
1. PiD: NVIDIA's pixel diffusion decoder reaches 2048×2048 in under one second
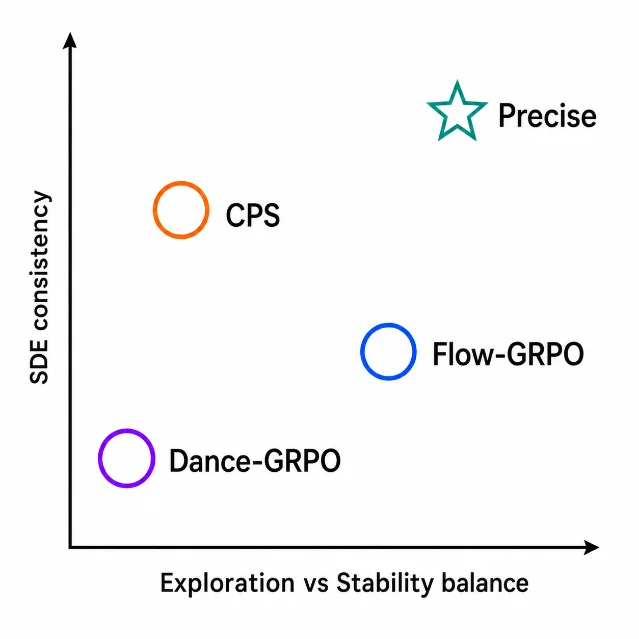
2. Precise: SDE-consistent stochastic sampling cuts RL training time by 13–53%
3. VDE: training-free rectified flow acceleration, 3.22× on Flux, CVPR 2026

4. Relay: forward-thinking discrete diffusion cuts inference latency by 32%
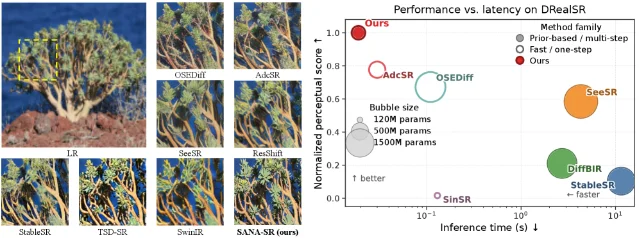
5. SANA-SR: one-step diffusion super-resolution in 0.019 seconds
Quick reference
| Paper | Core contribution | Institution | Peer-review status | Code |
|---|---|---|---|---|
| 2605.23902 — PiD | Sigma-aware adapter unifies latent decoding + upsampling; <1 s for 2048×2048 on RTX 5090, 6× faster than cascaded SR | NVIDIA Research (Toronto SIL Lab) | Preprint | GitHub (open) |
| 2605.23522 — Precise | Frozen clean-latent posterior mean ensures SDE consistency in RL rollouts; 13–53% less training wall-clock time | Tencent Hunyuan + Peking University | Preprint | Not confirmed |
| 2605.23381 — VDE | Velocity decompose-and-estimate replaces caching; 3.22× on Flux, LPIPS −52% vs EasyCache on Qwen-Image | South China University of Technology | CVPR 2026 | Not confirmed |
| 2605.22967 — Relay | Per-token relay channels enable forward-thinking in MDMs; 32% inference latency reduction on Fast-dLLM v2 | UMass Amherst / UofT / Stanford / ICL / Mila | Preprint | GitHub (open) |
| 2605.23451 — SANA-SR | 32× compression + linear attention + LoRA enables 0.019 s one-step SR at 344M params | SJTU + Fuzhou Univ + Shanghai AI Lab | Preprint | Not confirmed |
参考来源
- 1PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion (arXiv 2605.23902)
- 2Precise: SDE-Consistent Stochastic Sampling for RL Post-Training of Flow-Matching Models (arXiv 2605.23522)
- 3VDE: Training-Free Accelerating Rectified Flow Model via Velocity Decomposition and Estimation (arXiv 2605.23381)
- 4Learned Relay Representations for Forward-Thinking Discrete Diffusion Models (arXiv 2605.22967)
- 5Efficient One-Step Diffusion Restoration Model with Compact Token Compression and Linear Attention (arXiv 2605.23451)
围绕这条内容继续补充观点或上下文。